[Python]Kindle Unlimitedの購読履歴をエクスポートする
Contents
はじめに
2020年になりました。昨年どんな本を読んだか振り返ろうとしたときに、リストを作るのが面倒だったので書いてみました。
概要
流れは以下です。
- Amazonから履歴を取得し、HTMLファイルとして保存
- BeatufifulSoupを使ってスクレイピングし、ファイルに書き出し
Amazonから履歴を取得し、HTMLファイルとして保存
まず、Google ChromeでAmazonにログインし、「アカウント&リスト」 > 「お客様の Kindle Unlimited」と進みます。ここで過去に利用した本が確認できます。
そのままだと最新10件しか表示されていないので、画面をスクロールして必要な箇所まで読み込みます。
次に、右クリック > 検証 で検証ツールを立ち上げ、Elementsタブを開いて上部にある<body>タグを選択してコピーし、HTMLファイルとして保存します。
ファイル名はkindle_history.htmlとします。(なんでも良いです)
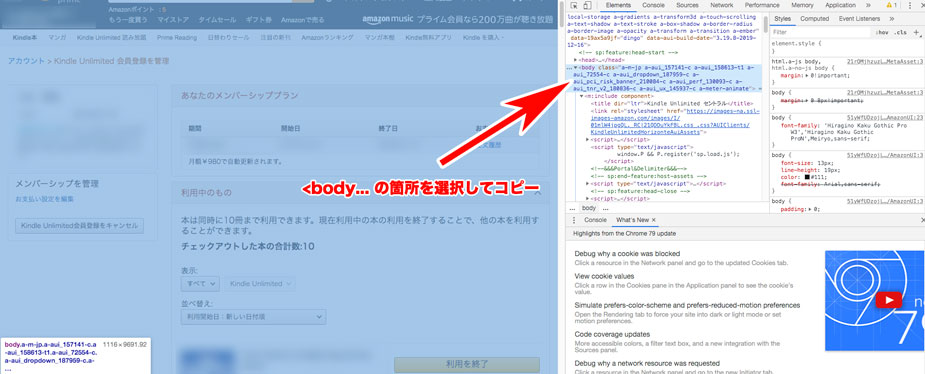
これでHTMLファイルの準備ができました。
BeatufifulSoupを使ってスクレイピングし、ファイルに書き出し
BeautifulSoupをインストール
インストールがまだならインストールします。
$ pip install beautifulsoup4
実装コード
kindle_scraper.py
import sys
from bs4 import BeautifulSoup
def export_kindle_unlimited_history(ifile, ofile=''):
html = open(ifile, 'r')
bsObj = BeautifulSoup(html, 'html.parser')
data = bsObj.find_all('span', attrs={'class':"a-size-base-plus a-text-bold"})
data = [d.contents[0] for d in data]
data = [d.strip() for d in data]
if ofile == '':
ofile = ifile + '_result.tsv'
with open(ofile, 'w') as fw:
for d in data:
print(d, file=fw)
if __name__ == '__main__':
argv = sys.argv
if len(argv) < 2:
print("""Set filepaths.
1: input filepath
2: output filepath (Option)
""")
sys.exit()
ifile = argv[1]
if len(argv) == 3:
ofile = argv[2]
else:
ofile = ''
export_kindle_unlimited_history(ifile, ofile)
実行
前項で保存したHTMLファイルのパスを指定してスクリプトを実行すればOKです。
同ディレクトリに指定したファイルパス + _result.tsvというファイル名で結果が保存されます。
$ python kindle_scraper.py kinle_history.html
まとめ
ブラウザ操作やAmazonへのログインをPythonで完結させるのは面倒だったのでHTMLファイルを取ってくるのは手作業にしました。
また、今回はタイトルだけ抽出しましたが、少しいじれば著者名や利用開始日などの情報も取得できると思います。